What is a neural network
Contents
%matplotlib inline
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
What is a neural network#
Neural network is a collection of neurons that are connected by layers. Each neuron is a small computing unit that performs simple calculations to collectively solve a problem. They are organized in layers. There are 3 types of layers: input layer, hidden layer and outter layer. Each layer contains a number of neurons, except for the input layer. Neural networks mimic the way a human brain processes information.

Components of a neural network#
Activation function determines whether a neuron should be activated or not. The computations that happen in a neural network include applying an activation function. If a neuron activates, then it means the input is important. The are different kinds of activation functions. The choice of which activation function to use depends on what you want the output to be. Another important role of an activation function is to add non-linearity to the model.
Binary used to set an output node to 1 if function result is positive and 0 if the function result is negative. \(f(x)= {\small \begin{cases} 0, & \text{if } x < 0\\ 1, & \text{if } x\geq 0\\ \end{cases}}\)
Sigmod is used to predict the probability of an output node being between 0 and 1. \(f(x) = {\large \frac{1}{1+e^{-x}}} \)
Tanh is used to predict if an output node is between 1 and -1. Used in classification use cases. \(f(x) = {\large \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}} \)
ReLU used to set the output node to 0 if fuction result is negative and keeps the result value if the result is a positive value. \(f(x)= {\small \begin{cases} 0, & \text{if } x < 0\\ x, & \text{if } x\geq 0\\ \end{cases}}\)
Weights influence how well the output of our network will come close to the expected output value. As an input enters the neuron, it gets multiplied by a weight value and the resulting output is either observed or passed to the next layer in the neural network. Weights for all neurons in a layer are organized into one tensor
Bias makes up the difference between the activation function’s output and its intended output. A low bias suggests that the network is making more assumptions about the form of the output, whereas a high bias value makes less assumptions about the form of the output.

We can say that an output \(y\) of a neural network layer with weights \(W\) and bias \(b\) is computed as a summation of the inputs multiplied by the weights plus the bias \(x = \sum{(weights * inputs) + bias} \), where \(f(x)\) is the activation function.
Build the Neural Network#
Neural networks comprise of layers/modules that perform operations on data. The torch.nn namespace provides all the building blocks you need to build your own neural network. Every module in PyTorch subclasses the nn.Module. A neural network is a module itself that consists of other modules (layers). This nested structure allows for building and managing complex architectures easily.
In the following sections, we’ll build a neural network to classify images in the FashionMNIST dataset.
Get Device for Training#
We want to be able to train our model on a hardware accelerator like the GPU, if it is available. Let’s check to see if torch.cuda is available, else we continue to use the CPU.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
Using cuda device
Define the Class#
We define our neural network by subclassing
nn.Moduleinitialize the neural network layers in
__init__.Every
nn.Modulesubclass implements the operations on input data in theforwardmethod.
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
We create an instance of NeuralNetwork, and move it to the device, and print
its structure.
model = NeuralNetwork().to(device)
print(model)
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
To use the model, we pass it the input data. This executes the model’s forward,
along with some background operations.
Do not call model.forward() directly!
Calling the model on the input returns a 2-dimensional tensor with dim=0 corresponding to each output of 10 raw predicted values for each class, and dim=1 corresponding to the individual values of each output. .
We get the prediction probabilities by passing it through an instance of the nn.Softmax module.
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
Predicted class: tensor([0], device='cuda:0')
Model Layers#
Let’s break down the layers in the FashionMNIST model. To illustrate it, we will take a sample minibatch of 3 images of size 28x28 and see what happens to it as we pass it through the network.
input_image = torch.rand(3, 28, 28)
print(input_image.size())
torch.Size([3, 28, 28])
nn.Flatten#
We initialize the nn.Flatten layer to convert each 2D 28x28 image into a contiguous array of 784 pixel values ( the minibatch dimension (at dim=0) is maintained).
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
torch.Size([3, 784])
nn.Linear#
The linear layer is a module that applies a linear transformation on the input using its stored weights and biases.
layer1 = nn.Linear(in_features=28 * 28, out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())
torch.Size([3, 20])
nn.ReLU#
Non-linear activations are what create the complex mappings between the model’s inputs and outputs. They are applied after linear transformations to introduce nonlinearity, helping neural networks learn a wide variety of phenomena.
In this model, we use nn.ReLU between our linear layers, but there’s other activations to introduce non-linearity in your model.

print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
Before ReLU: tensor([[ 7.0810e-01, -2.0234e-01, -2.7697e-02, -9.0180e-02, 6.0383e-01,
3.8660e-01, -6.3321e-02, -6.4357e-01, 1.3363e-01, -8.8465e-01,
7.4847e-02, 7.2338e-01, -1.7347e-01, -9.6468e-02, 2.2572e-01,
7.0648e-01, -2.6426e-01, 2.4609e-01, -7.5594e-02, 2.4092e-01],
[ 2.0843e-01, -4.3973e-02, 5.6758e-02, 1.1729e-01, 3.3175e-01,
-5.4562e-02, -1.4041e-01, -5.2778e-01, -2.9531e-01, -6.5065e-01,
3.7667e-01, 2.3575e-01, -8.9535e-02, -7.1310e-02, -1.1409e-01,
3.8473e-01, -2.9001e-02, 7.3168e-02, 2.1666e-01, -2.8219e-01],
[ 1.2027e-01, -5.4479e-02, -3.4571e-02, 8.6609e-02, 2.6646e-01,
2.1801e-01, 1.3120e-05, -2.4486e-01, -4.0915e-02, -5.6223e-01,
4.0318e-01, 1.1474e+00, -2.5827e-01, -1.5660e-01, -1.6509e-01,
4.5950e-01, -3.2235e-01, -4.1041e-02, -1.1736e-01, -2.5513e-01]],
grad_fn=<AddmmBackward0>)
After ReLU: tensor([[7.0810e-01, 0.0000e+00, 0.0000e+00, 0.0000e+00, 6.0383e-01, 3.8660e-01,
0.0000e+00, 0.0000e+00, 1.3363e-01, 0.0000e+00, 7.4847e-02, 7.2338e-01,
0.0000e+00, 0.0000e+00, 2.2572e-01, 7.0648e-01, 0.0000e+00, 2.4609e-01,
0.0000e+00, 2.4092e-01],
[2.0843e-01, 0.0000e+00, 5.6758e-02, 1.1729e-01, 3.3175e-01, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 3.7667e-01, 2.3575e-01,
0.0000e+00, 0.0000e+00, 0.0000e+00, 3.8473e-01, 0.0000e+00, 7.3168e-02,
2.1666e-01, 0.0000e+00],
[1.2027e-01, 0.0000e+00, 0.0000e+00, 8.6609e-02, 2.6646e-01, 2.1801e-01,
1.3120e-05, 0.0000e+00, 0.0000e+00, 0.0000e+00, 4.0318e-01, 1.1474e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 4.5950e-01, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00]], grad_fn=<ReluBackward0>)
nn.Sequential#
nn.Sequential is an ordered
container of modules. The data is passed through all the modules in the same order as defined. You can use
sequential containers to put together a quick network like seq_modules.
seq_modules = nn.Sequential(flatten, layer1, nn.ReLU(), nn.Linear(20, 10))
input_image = torch.rand(3, 28, 28)
logits = seq_modules(input_image)
nn.Softmax#
The last linear layer of the neural network returns logits - raw values in [-\infty, \infty] - which are passed to the
nn.Softmax module. The logits are scaled to values
[0, 1] representing the model’s predicted probabilities for each class. dim parameter indicates the dimension along
which the values must sum to 1.
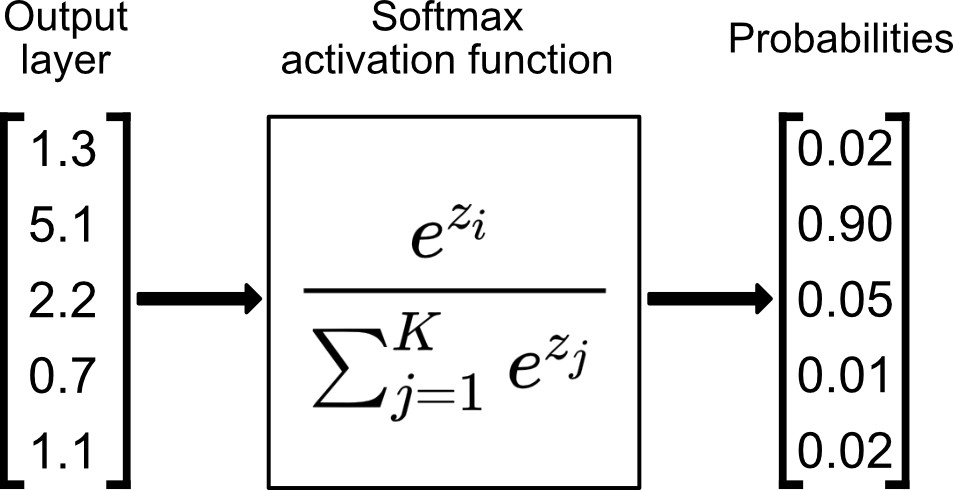
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
Model Parameters#
Many layers inside a neural network are parameterized, i.e. have associated weights
and biases that are optimized during training. Subclassing nn.Module automatically
tracks all fields defined inside your model object, and makes all parameters
accessible using your model’s parameters() or named_parameters() methods.
In this example, we iterate over each parameter, and print its size and a preview of its values.
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")
Model structure: NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values : tensor([[ 0.0021, 0.0258, -0.0276, ..., 0.0315, -0.0089, 0.0307],
[ 0.0139, 0.0249, 0.0272, ..., -0.0157, -0.0191, -0.0050]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values : tensor([ 0.0071, -0.0012], device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values : tensor([[-0.0160, -0.0256, -0.0424, ..., -0.0171, -0.0241, 0.0239],
[ 0.0402, 0.0244, 0.0249, ..., 0.0192, 0.0411, 0.0119]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values : tensor([0.0436, 0.0158], device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values : tensor([[ 0.0296, 0.0336, 0.0429, ..., 0.0228, -0.0302, -0.0070],
[-0.0100, 0.0175, -0.0004, ..., -0.0153, 0.0346, 0.0309]],
device='cuda:0', grad_fn=<SliceBackward0>)
Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values : tensor([-0.0206, 0.0267], device='cuda:0', grad_fn=<SliceBackward0>)