
🎯 Overfitting and Underfitting in Machine Learning: The Balancing Act ⚖️#
Imagine you’re an engineer designing a system to recognize faulty components on an assembly line. You train your machine learning model with thousands of images, and it performs flawlessly on the training data. But when you deploy it on the live production line, it starts making mistakes! 😱
What went wrong? It’s the classic battle between Overfitting and Underfitting! Let’s explore these two villains that can ruin your machine learning models and learn how to defeat them! 🦸♂️🦸♀️
🧠 What are Overfitting and Underfitting?#
These are two common problems that occur when training machine learning models:
🎩 Overfitting: When Your Model is Too Smart…#
Definition: The model learns the training data too well, even capturing the noise and outliers.
Result: Great performance on training data, but poor generalization to new, unseen data.
In Simple Words: Your model becomes a “memorization machine” instead of a “generalization genius.”
Example:
Imagine an engineer who memorizes every blueprint, including minor smudges and imperfections. When shown a new, clean blueprint, they get confused because the smudges are missing! 😵
🎈 Underfitting: When Your Model is Too Simple…#
Definition: The model is too simplistic to capture the patterns in the training data.
Result: Poor performance on both training and testing data.
In Simple Words: Your model is like a student who didn’t study enough and doesn’t understand the subject well.
Example:
A junior engineer who only knows basic formulas and can’t handle complex problems because they didn’t learn enough. 😕
🔍 How to Identify Overfitting and Underfitting#
📉 Overfitting Symptoms:#
High accuracy on training data but low accuracy on testing data.
Large gap between training and validation error.
Example:
In manufacturing, your model accurately classifies defective parts in historical data but fails on new production batches.
📉 Underfitting Symptoms:#
Low accuracy on both training and testing data.
High bias: The model makes overly simplistic assumptions.
Example:
A model that always predicts the average product quality, regardless of input features.
🔨 Visualizing Overfitting and Underfitting#
Imagine fitting a curve to data points:
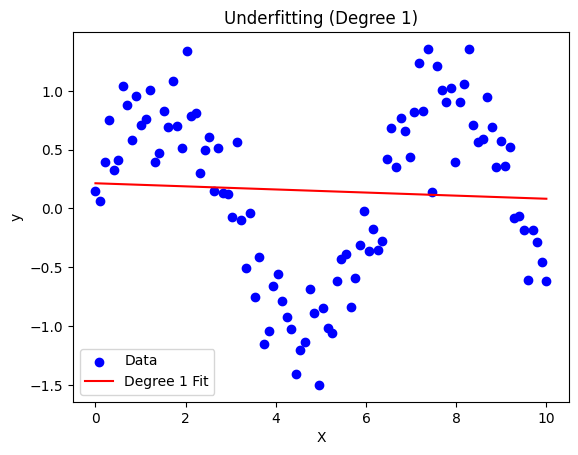
Underfitting: The model is a straight line that barely touches any points.
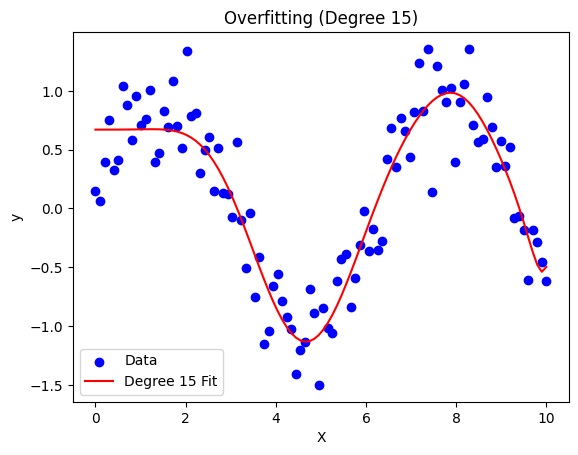
Overfitting: The model is a wiggly line that passes through every point, including noise.
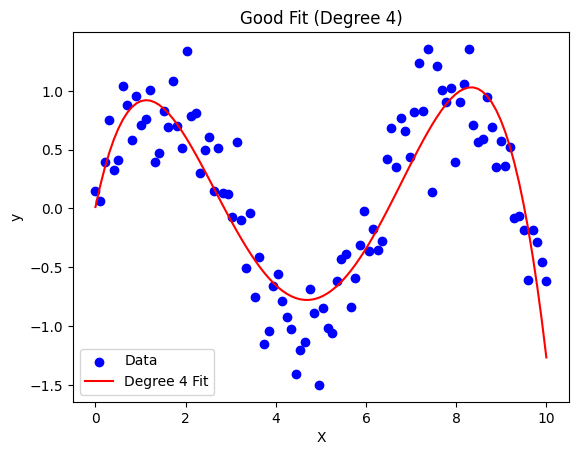
Just Right (Generalization): The model captures the underlying pattern without chasing noise.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Generate synthetic data
np.random.seed(42)
X = np.linspace(0, 10, 100).reshape(-1, 1)
y = np.sin(X).ravel() + np.random.normal(0, 0.3, X.shape[0])
# Function to plot models
def plot_model(degree, title):
poly = PolynomialFeatures(degree)
X_poly = poly.fit_transform(X)
model = LinearRegression().fit(X_poly, y)
y_pred = model.predict(X_poly)
plt.scatter(X, y, color="blue", label="Data")
plt.plot(X, y_pred, color="red", label=f"Degree {degree} Fit")
plt.title(title)
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.show()
# Underfitting
plot_model(1, "Underfitting (Degree 1)")
# Good Fit
plot_model(4, "Good Fit (Degree 4)")
# Overfitting
plot_model(15, "Overfitting (Degree 15)")
🔍 What You’ll See:#
Underfitting (Degree 1): A straight line missing the patterns.
Good Fit (Degree 4): A smooth curve capturing the pattern.
Overfitting (Degree 15): A complex curve oscillating through every point.
🧑🔧 Engineering Examples#
⚙️ Example 1: Predictive Maintenance#
Overfitting: The model memorizes specific failure times instead of learning general patterns from temperature and vibration data.
Underfitting: The model only considers the average lifetime, ignoring valuable sensor data.
🛠️ Example 2: Quality Control in Manufacturing#
Overfitting: Memorizes defects in historical batches but fails on new designs.
Underfitting: Labels most products as “average quality,” missing subtle defects.
🛡️ How to Combat Overfitting#
1. Cross-Validation 🧪#
Use k-fold cross-validation to ensure the model generalizes well.
Split data into multiple training and testing sets and average the results.
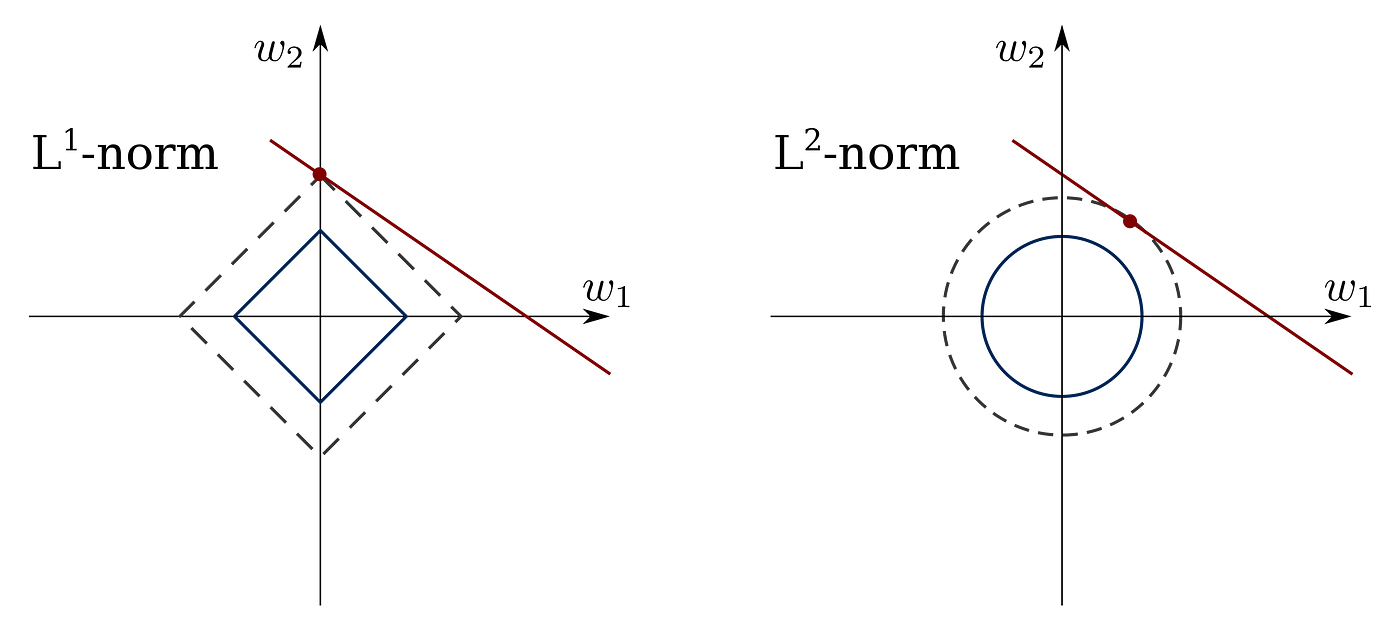
2. Regularization 🔗#
Add a penalty to the model complexity.
L1 (Lasso) and L2 (Ridge) regularization are commonly used techniques.
In Scikit-learn:
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)
3. Early Stopping ⏰#
Stop training when validation error starts to increase, preventing overfitting.
4. Pruning 🌳#
For decision trees, prune branches that have little importance.
5. Ensemble Methods 👥#
Combine multiple models to reduce overfitting.
Example: Random Forests and Gradient Boosting.
6. Dropout (for Neural Networks) 💧#
Randomly drop neurons during training to prevent memorization.
🛡️ How to Combat Underfitting#
1. Increase Model Complexity 🔧#
Use more complex models (e.g., increase the depth of decision trees or layers in neural networks).
2. Feature Engineering 🔍#
Add more relevant features or create new ones using domain knowledge.
3. Decrease Regularization ➖#
If regularization is too strong, reduce it to allow the model to learn more patterns.
4. Ensemble Methods 👥#
Using ensemble methods like Random Forests can also improve model complexity.
🔍 What You’ll Observe:#
The Overfitting Model performs well on training but poorly on testing.
The Ridge Model balances the errors, improving generalization.
🎉 Key Takeaways#
Overfitting: Model is too complex and memorizes noise.
Underfitting: Model is too simple and misses patterns.
Goal: Achieve Generalization by finding the sweet spot between bias and variance.